1 引言
DataX 是一个异构数据源离线同步工具,主要应用与不同数据源之间的数据同步
根据官方的架构图

Datax主要分为三个模块
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
2 Datax运行流程图
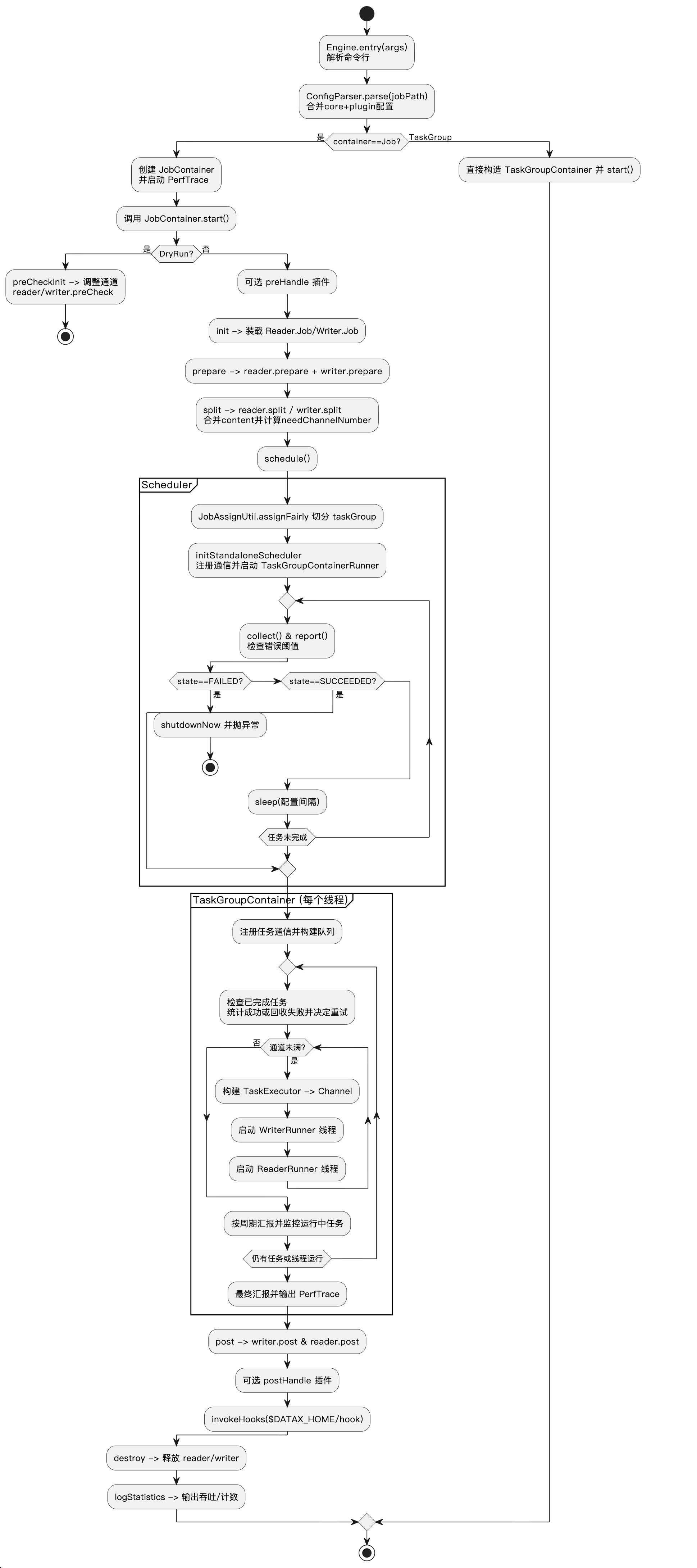
3 DataX源码分析
3.1 核心架构与框架设计
DataX 的运行时围绕”容器 + 插件”的分层设计展开:命令行入口 Engine 负责解析作业配置、绑定插件元数据,并根据运行模式实例化 JobContainer 或 TaskGroupContainer,之后统一初始化性能跟踪并启动对应容器。容器层对外提供统一的生命周期,而具体的读写与数据搬运逻辑则完全由插件实现,实现了控制面与数据面的解耦。
整体的数据链路大致为:
Engine(入口)→ JobContainer(作业编排)→ Scheduler(全局调度)→ TaskGroupContainer/TaskExecutor(并发执行)→ Channel + 插件(数据读写)
核心类
JobContainer:作为作业级 Master,串联preHandle → init → prepare → split → schedule → post/postHandle → destroy/statistics的全生命周期;其中会加载 Reader/Writer 的 Job 实例、执行预检查、按速率限制计算所需 Channel 数、并调用JobAssignUtil公平分配 taskGroup 后启动调度器。AbstractScheduler/StandAloneScheduler:调度层收集 TaskGroup 状态、定期上报、进行错误阈值校验,并根据状态触发失败/终止处理,保证所有任务都被正确调度和回收。TaskGroupContainer:在工作线程中维护任务队列、失败重试和周期汇报,依据 Channel 上限启动TaskExecutor,并在异常或完成时汇总通信状态。TaskGroupContainer.TaskExecutor:Task 内部执行器,将一个 Reader/Writer Task 与共享的Channel绑定;分别构建ReaderRunner、WriterRunner线程,注入通信器、脏数据收集器以及(可选)Transformer 管道,从而实现 1:1 的读写配对和数据流转。
3.1.1 Engine启动与配置解析
Engine启动流程
- 命令行入口
Engine.entry使用 Commons CLI 定义--job/--jobid/--mode参数并解析,随后调用ConfigParser.parse读取作业配置,同时初始化多语言资源包。 - 如果用户未显式提供
jobId,入口会尝试从历史调度 URL 中提取;在非standalone模式下强制要求得到有效的 jobId,并将其写回配置对象供后续组件使用。 - 在真正启动容器前,入口打印当前 JVM 信息以及脱敏后的作业 JSON(会对
password/accessKey等字段打码),然后调用ConfigurationValidate.doValidate做最基本的非空校验并进入start。 - 若
entry抛出异常,main会根据FrameworkErrorCode转成进程退出码,并输出经ExceptionTracker处理的堆栈,保证脚本层能感知失败原因。
配置解析细节
ConfigParser.parse() (core/.../util/ConfigParser.java:25) 将配置组装分为三个阶段:
阶段一:解析作业配置。 parseJobConfig 支持本地文件路径和 HTTP URL 两种来源。本地走 FileUtils.readFileToString,远程走 HttpClientUtil 并带 1 次失败重试。读取到的 JSON 字符串经 Configuration.from 解析后,还会通过 SecretUtil.decryptSecretKey 对加密字段解密。
阶段二:合并框架配置。 读取 {DATAX_HOME}/conf/core.json(路径由 CoreConstant.DATAX_CONF_PATH 定义),以 merge(coreConfig, false) 的方式合并到作业配置中——false 表示作业配置优先,不会被框架默认值覆盖。
阶段三:发现并合并插件配置。 从作业配置中提取 reader/writer/preHandler/postHandler 的插件名,收集到 pluginList 中。parsePluginConfig 遍历 {DATAX_HOME}/plugin/reader/ 和 {DATAX_HOME}/plugin/writer/ 下的所有子目录,逐个读取 plugin.json。核心逻辑在 parseOnePluginConfig:
// ConfigParser.java:149
String pluginName = configuration.getString("name");
// 仅加载 wantPluginNames 中指定的插件,其余跳过
if (wantPluginNames != null && !wantPluginNames.contains(pluginName)) {
return null;
}
// 若 plugin.json 未指定 path,则使用插件目录自身作为 jar 加载路径
if (StringUtils.isBlank(pluginPath)) {
configuration.set("path", path);
configuration.set("loadType", "jarLoader");
}
// 按 plugin.<type>.<name> 的 key 结构写入总配置
result.set(String.format("plugin.%s.%s", type, pluginName), configuration.getInternal());插件加载包含一次重试机制:首次 parsePluginConfig 失败后等待 1 秒再重试,保证在插件 jar 尚未就绪时有一定容错。
3.1.2 Container抽象与实现
AbstractContainer (core/.../AbstractContainer.java) 是所有执行容器的基类,持有全局 Configuration 和 AbstractContainerCommunicator,定义了唯一的抽象方法 start(),由子类实现具体的生命周期逻辑。
@startuml
abstract class AbstractContainer {
# configuration : Configuration
# containerCommunicator : AbstractContainerCommunicator
+ {abstract} start() : void
+ getConfiguration() : Configuration
+ setContainerCommunicator(c) : void
}
class JobContainer extends AbstractContainer {
- jobId : long
- jobReader : Reader.Job
- jobWriter : Writer.Job
- needChannelNumber : int
- errorLimit : ErrorRecordChecker
+ start() : void
- init() / prepare() / split() / schedule()
- preHandle() / postHandle()
- post() / destroy() / logStatistics()
}
class TaskGroupContainer extends AbstractContainer {
- jobId : long
- taskGroupId : int
- channelClazz : String
- taskMonitor : TaskMonitor
+ start() : void
}
AbstractContainer <|-- JobContainer
AbstractContainer <|-- TaskGroupContainer
@endumlJobContainer:作业级 Master,在start()中串联 7 个阶段的生命周期,负责插件初始化、任务拆分、调度启动和最终统计。TaskGroupContainer:任务组级执行器,在start()中运行 while 循环,管理任务队列、并发上限和周期汇报。
两者均通过 ContainerCommunicator 与上层通信,实现统计信息的层级聚合。
3.1.3 整体架构设计理念与模式
DataX 的架构围绕三个核心设计理念展开:
1. 容器 + 插件分层。 框架层(Container/Scheduler/Channel)负责生命周期管理、调度和传输;插件层(Reader/Writer/Transformer)负责具体的数据读写和转换。两层通过 RecordSender/RecordReceiver 接口解耦,框架无需感知数据源细节。
2. ClassLoader 隔离。 每个插件通过 JarLoader(继承 URLClassLoader)加载独立的 jar 包,配合 ClassLoaderSwapper 在执行前后切换线程上下文 ClassLoader,避免不同插件间的依赖冲突(如多版本 MySQL Driver 共存)。
3. 控制面 / 数据面解耦。 控制面由 JobContainer → Scheduler → TaskGroupContainer 构成,负责任务编排、调度和监控;数据面由 ReaderRunner → Channel → WriterRunner 构成,负责实际的数据搬运。两者通过 Communication 对象交换状态。
@startuml
package "控制面 (Control Plane)" {
[Engine] --> [JobContainer]
[JobContainer] --> [AbstractScheduler]
[AbstractScheduler] --> [TaskGroupContainer]
}
package "数据面 (Data Plane)" {
[ReaderRunner] --> [BufferedRecordExchanger]
[BufferedRecordExchanger] --> [Channel]
[Channel] --> [BufferedRecordExchanger2]
[BufferedRecordExchanger2] --> [WriterRunner]
}
package "插件层 (Plugin Layer)" {
[Reader Plugin] ..> [ReaderRunner] : 被加载
[Writer Plugin] ..> [WriterRunner] : 被加载
[JarLoader] ..> [Reader Plugin] : ClassLoader隔离
[JarLoader] ..> [Writer Plugin] : ClassLoader隔离
}
[TaskGroupContainer] --> [ReaderRunner] : 创建TaskExecutor
[TaskGroupContainer] --> [WriterRunner]
[Communication] <.. [TaskGroupContainer] : 状态上报
[Communication] <.. [AbstractScheduler] : 状态聚合
@enduml3.2 任务调度与执行模型
3.2.1 JobContainer工作机制
JobContainer.start() (core/.../job/JobContainer.java:96) 定义了作业的完整生命周期,分为 7 个阶段:
@startuml
start
:preHandle\n加载 preHandler 插件并执行;
:init\n初始化 Reader.Job 和 Writer.Job 实例;
:prepare\n调用 Reader/Writer 的 prepare();
:split\n计算 channelNumber 并拆分任务;
:schedule\n公平分配 TaskGroup 并启动调度器;
:post\n调用 Writer/Reader 的 post();
:postHandle\n加载 postHandler 插件并执行;
stop
note right of :split
1. adjustChannelNumber() 计算并发度
2. doReaderSplit(needChannelNumber)
3. doWriterSplit(readerTaskNumber)
4. mergeReaderAndWriterTaskConfigs()
end note
note right of :schedule
1. JobAssignUtil.assignFairly() 分配任务到 TaskGroup
2. 初始化 StandAloneScheduler
3. scheduler.schedule(taskGroupConfigs)
4. checkLimit() 校验脏数据阈值
end note
@enduml关键实现细节:
- init 阶段:通过
LoadUtil.loadJobPlugin反射创建 Reader.Job/Writer.Job 实例,设置各自的pluginJobConf和peerPluginJobConf(对端配置),并调用init()让插件完成自身初始化。全程通过ClassLoaderSwapper隔离 ClassLoader。 - split 阶段:先调用
adjustChannelNumber()根据 byte/record/channel 限速计算所需 Channel 数,再将该值作为adviceNumber传给 Reader 拆分,Writer 则必须拆出与 Reader 等量的 Task。最后将 Reader/Writer 的 Task 配置 1:1 合并为content列表。 - schedule 阶段:调用
JobAssignUtil.assignFairly将 Task 公平分配到若干 TaskGroup,每组分配channelsPerTaskGroup(默认 5)个 Channel。随后创建StandAloneScheduler,执行scheduler.schedule(taskGroupConfigs)启动所有 TaskGroup。 - 异常处理:
start()的 catch 块会收集 Communication 状态并上报,finally 块确保调用destroy()释放资源并打印最终统计(任务耗时、平均流量、记录数等)。OOM 时会先destroy()再System.gc()。
3.2.2 TaskGroupContainer任务组管理
TaskGroupContainer.start() (core/.../taskgroup/TaskGroupContainer.java:93) 在独立线程中运行 while 循环,管理一组 Task 的并发执行:
@startuml
start
:初始化 taskQueue / runTasks / taskConfigMap;
while (任务未全部完成?) is (是)
:遍历 runTasks 检查各 Task 状态;
if (Task FAILED?) then (是)
if (支持 failover 且未超重试次数?) then (是)
:shutdown Task, reset Communication;
:重新加入 taskQueue 等待重试;
else (否)
:标记 TaskGroup 失败, 抛出异常;
endif
elseif (Task KILLED?) then (是)
:标记失败, 抛出异常;
elseif (Task SUCCEEDED?) then (是)
:从 runTasks 移除;
:记录完成指标;
endif
:从 taskQueue 取任务补充到 runTasks;
note right: 受 channelNumber 上限控制
:创建 TaskExecutor 并 doStart();
if (到达汇报间隔?) then (是)
:reportTaskGroupCommunication();
endif
:sleep(sleepIntervalInMillSec);
endwhile (否)
:最终汇报 TaskGroup 状态;
stop
@enduml核心控制变量:
channelNumber:该 TaskGroup 的并发上限,即同时运行的 TaskExecutor 数量。taskMaxRetryTimes(默认 1):单个 Task 的最大重试次数。taskRetryIntervalInMsec(默认 10s):重试前等待时间。taskMaxWaitInMsec(默认 60s):等待退出的最大时间。reportIntervalInMillSec:周期汇报间隔,每次汇报会将所有 Task 的 Communication 聚合后上报。
3.2.3 TaskExecutor执行器实现
TaskExecutor 是 TaskGroupContainer 的内部类,封装了单个 Reader-Writer Task 的执行单元。
@startuml
participant TaskGroupContainer as TGC
participant TaskExecutor as TE
participant WriterRunner as WR
participant ReaderRunner as RR
participant Channel as CH
participant BufferedRecordExchanger as BRE
TGC -> TE : new TaskExecutor(taskConfig, attemptCount)
activate TE
TE -> CH : 反射创建 Channel 实例
TE -> BRE : 创建 writerExchanger (RecordReceiver)
TE -> WR : new WriterRunner(writerPlugin, writerExchanger)
TE -> BRE : 创建 readerExchanger (RecordSender)
TE -> RR : new ReaderRunner(readerPlugin, readerExchanger)
note right: 若有 Transformer 则使用\nBufferedRecordTransformerExchanger
TE -> WR : writerThread.setContextClassLoader(writerJarLoader)
TE -> RR : readerThread.setContextClassLoader(readerJarLoader)
deactivate TE
TGC -> TE : doStart()
activate TE
TE -> WR : writerThread.start()
activate WR
TE -> RR : readerThread.start()
activate RR
RR -> BRE : sendToWriter(record)
BRE -> CH : push(records)
CH -> BRE : pull(records)
BRE -> WR : getFromReader()
RR -> BRE : terminate()
note right: 发送 TerminateRecord 信号
BRE -> WR : return null (EOF)
deactivate RR
deactivate WR
deactivate TE
@enduml组装过程:
- 反射创建
Channel实例(默认MemoryChannel),设置capacity、byteCapacity、流控参数。 - 通过
LoadUtil.loadTaskPlugin加载 Reader.Task 和 Writer.Task 实例。 - 构建
BufferedRecordExchanger(或含 Transformer 的BufferedRecordTransformerExchanger)作为 Reader 端的RecordSender和 Writer 端的RecordReceiver。 - 将
ReaderRunner/WriterRunner封装到独立线程,并设置各自的JarLoader为线程上下文 ClassLoader。 doStart()先启动 Writer 线程(确保消费端就绪),再启动 Reader 线程。
3.2.4 任务生命周期管理
每个 Task 在 TaskGroupContainer 的管理下经历如下状态流转:
@startuml
[*] --> WAITING : 加入 taskQueue
WAITING --> RUNNING : TaskExecutor.doStart()
RUNNING --> SUCCEEDED : Reader/Writer 均正常完成
RUNNING --> FAILED : Reader 或 Writer 抛出异常
RUNNING --> KILLED : 外部终止信号
FAILED --> WAITING : supportFailOver()\n且 attemptCount < maxRetryTimes
FAILED --> [*] : 不支持 failover\n或超过重试次数 → 整个 TaskGroup 失败
SUCCEEDED --> [*] : 从 runTasks 移除
KILLED --> [*] : 整个 TaskGroup 失败
@enduml状态判定逻辑(TaskGroupContainer.start() 循环体内):
- SUCCEEDED:
taskExecutor.isTaskFinished()返回 true(Reader/Writer 线程均结束),且Communication.state == SUCCEEDED。 - FAILED:
Communication.state == FAILED,通常由ReaderRunner或WriterRunner的markFail(e)触发。 - KILLED:
Communication.state == KILLED,由外部调度系统设置(standalone 模式下不会触发)。
重试机制:Task 失败后若 Writer.Task.supportFailOver() 返回 true 且 attemptCount < taskMaxRetryTimes,则 shutdown 当前 TaskExecutor、重置 Communication、将 taskConfig 重新入队。重试前会等待 taskRetryIntervalInMsec。
3.3 数据传输与通道机制
3.3.1 Channel实现原理
Channel (core/.../transport/channel/Channel.java) 是数据传输的抽象基类,采用模板方法模式将流控统计与实际传输分离。
@startuml
abstract class Channel {
# capacity : int = 2048
# byteCapacity : int = 8MB
# byteSpeed : long
# recordSpeed : long
# flowControlInterval : long = 1000ms
- currentCommunication : Communication
- lastCommunication : Communication
+ push(Record) : void
+ pull() : Record
+ pushAll(Collection<Record>) : void
+ pullAll(Collection<Record>) : void
# {abstract} doPush(Record)
# {abstract} doPull() : Record
# {abstract} doPushAll(Collection<Record>)
# {abstract} doPullAll(Collection<Record>)
- statPush(long bytes, long count)
- statPull(long bytes, long count)
}
class MemoryChannel extends Channel {
- queue : ArrayBlockingQueue<Record>
- lock : ReentrantLock
- notSufficient : Condition
- notEmpty : Condition
- memoryBytes : AtomicInteger
- bufferSize : int
# doPush(Record)
# doPull() : Record
# doPushAll(Collection<Record>)
# doPullAll(Collection<Record>)
}
Channel <|-- MemoryChannel
@enduml流控算法(Channel.statPush()):每次 push 后累加统计量,当距上次检查超过 flowControlInterval 时计算当前吞吐:
- 若
byteSpeed > 0且当前字节速率超限,计算需要 sleep 的毫秒数使速率降至限制值以下。 - 若
recordSpeed > 0且当前记录速率超限,同理计算 sleep 时间。 - 取两者中较大的 sleep 值执行。
MemoryChannel (core/.../channel/memory/MemoryChannel.java) 基于 ArrayBlockingQueue 实现:
- 单条记录:直接使用
queue.put()/queue.take()的内置阻塞同步。 - 批量操作:使用
ReentrantLock+Condition(notSufficient/notEmpty)实现有界批量传输,同时通过memoryBytes(AtomicInteger)跟踪内存占用,push 时判断memoryBytes + newBytes > byteCapacity则等待。
3.3.2 数据交换机制(Exchanger)
Exchanger 是 Reader/Writer 与 Channel 之间的缓冲层,减少对 Channel 的锁竞争。
@startuml
interface RecordSender {
+ createRecord() : Record
+ sendToWriter(Record)
+ flush()
+ terminate()
+ shutdown()
}
interface RecordReceiver {
+ getFromReader() : Record
+ shutdown()
}
class BufferedRecordExchanger implements RecordSender, RecordReceiver {
- channel : Channel
- buffer : List<Record>
- bufferSize : int = 2048
- byteCapacity : int = 8MB
- memoryBytes : AtomicInteger
- bufferIndex : int
- shutdown : volatile boolean
- pluginCollector : TaskPluginCollector
}
class BufferedRecordTransformerExchanger implements RecordSender, RecordReceiver {
- channel : Channel
- buffer : List<Record>
- transformerExecs : List<TransformerExecution>
+ doTransformer(Record) : Record
}
class TransformerExchanger {
# transformerExecs : List<TransformerExecution>
# doTransformer(Record) : Record
}
BufferedRecordTransformerExchanger --|> TransformerExchanger
@endumlBufferedRecordExchanger:无 Transformer 时使用,Reader 端调用sendToWriter(record)将记录写入本地 buffer,buffer 满时批量flush()到 Channel;Writer 端调用getFromReader()从本地 buffer 取数据,buffer 耗尽时批量receive()从 Channel 拉取。BufferedRecordTransformerExchanger:有 Transformer 时使用,继承TransformerExchanger。在sendToWriter中先调用doTransformer(record)逐条执行 Transformer 链,若返回 null 则表示该记录被过滤。
3.3.3 缓冲区设计
Buffer flush 采用双条件触发策略(以 BufferedRecordExchanger.sendToWriter() 为例):
// BufferedRecordExchanger.java:81
if (record.getMemorySize() > this.byteCapacity) {
// 单条记录超过 byteCapacity → 收集为脏数据
this.pluginCollector.collectDirtyRecord(record, ...);
return;
}
boolean isFull = (bufferIndex >= bufferSize)
|| (memoryBytes.get() + record.getMemorySize() >= byteCapacity);
if (isFull) {
flush(); // 批量 pushAll 到 Channel,清空 buffer
}
buffer.add(record);
bufferIndex++;
memoryBytes.addAndGet(record.getMemorySize());触发条件(满足任一即 flush):
- 记录数达到上限:
bufferIndex >= bufferSize(默认 2048,配置项core.transport.exchanger.bufferSize)。 - 内存占用达到上限:
memoryBytes + recordSize >= byteCapacity(默认 8MB)。
Writer 端拉取同样是批量操作:receive() 调用 channel.pullAll(buffer) 一次性拉取最多 bufferSize 条记录到本地 buffer,然后通过 bufferIndex 逐条返回给 Writer。
流控限速发生在 Channel 层而非 Buffer 层。Buffer 的职责仅是攒批以减少同步开销。
3.3.4 数据记录的流转过程
一条记录从 Reader 产生到 Writer 消费的完整路径:
@startuml
participant "Reader.Task" as RT
participant "RecordSender\n(BufferedRecordExchanger)" as RS
participant "本地Buffer\n(Reader侧)" as RB
participant "Channel\n(MemoryChannel)" as CH
participant "本地Buffer\n(Writer侧)" as WB
participant "RecordReceiver\n(BufferedRecordExchanger)" as RR
participant "Writer.Task" as WT
RT -> RS : createRecord()
RS --> RT : DefaultRecord 实例
RT -> RS : sendToWriter(record)
RS -> RB : buffer.add(record)
note right: 累计到 bufferSize 或 byteCapacity
RB -> RS : buffer 满触发 flush()
RS -> CH : channel.pushAll(buffer)
note right: Channel.statPush() 执行流控
WT -> RR : getFromReader()
RR -> WB : 检查本地 buffer
alt buffer 为空
RR -> CH : channel.pullAll(buffer)
CH --> WB : 批量拉取记录
end
WB --> RR : buffer[bufferIndex++]
RR --> WT : Record
== Reader 完成 ==
RT -> RS : terminate()
RS -> CH : flush() + push(TerminateRecord)
WT -> RR : getFromReader()
RR -> CH : pull TerminateRecord
RR --> WT : return null (EOF)
@endumlTerminateRecord 是一个特殊的哨兵记录,Reader 端在 terminate() 时发送,Writer 端在 getFromReader() 中检测到后返回 null,通知 Writer 数据已传输完毕。
3.4 插件体系设计
3.4.1 Reader/Writer接口设计
DataX 的插件继承体系采用 SPI 模式,通过抽象类层层扩展:
@startuml
interface Pluginable {
+ init() / destroy()
+ getPluginName() : String
+ getDeveloper() : String
+ setPluginConf(Configuration)
+ getPluginJobConf() : Configuration
+ getPeerPluginJobConf() : Configuration
}
abstract class AbstractPlugin implements Pluginable {
- pluginConf : Configuration
- pluginJobConf : Configuration
- peerPluginJobConf : Configuration
- peerPluginName : String
+ preCheck() / prepare() / post()
+ preHandler() / postHandler()
}
abstract class AbstractJobPlugin extends AbstractPlugin {
- jobPluginCollector : JobPluginCollector
}
abstract class AbstractTaskPlugin extends AbstractPlugin {
- taskGroupId : int
- taskId : int
- taskPluginCollector : TaskPluginCollector
}
abstract class "Reader.Job" as RJ extends AbstractJobPlugin {
+ {abstract} split(adviceNumber) : List<Configuration>
}
abstract class "Reader.Task" as RT extends AbstractTaskPlugin {
+ {abstract} startRead(RecordSender)
}
abstract class "Writer.Job" as WJ extends AbstractJobPlugin {
+ {abstract} split(mandatoryNumber) : List<Configuration>
}
abstract class "Writer.Task" as WT extends AbstractTaskPlugin {
+ {abstract} startWrite(RecordReceiver)
+ supportFailOver() : boolean
}
@enduml关键设计差异:
Reader.Job.split(adviceNumber):adviceNumber是框架建议的拆分数,Reader 可以返回更多或更少的 Task。Writer.Job.split(mandatoryNumber):mandatoryNumber等于 Reader 实际拆出的 Task 数,Writer 必须严格返回等量 Task,保证 1:1 配对。Writer.Task.supportFailOver():默认返回 false,若返回 true 则该 Task 失败后可被重试。
每个 Plugin 都持有对端配置(peerPluginJobConf),使得 Writer 可感知 Reader 的配置(如编码、分隔符等)。
3.4.2 插件加载机制
插件的加载由 LoadUtil、JarLoader、ClassLoaderSwapper 三个类协作完成:
@startuml
participant "JobContainer" as JC
participant "LoadUtil" as LU
participant "JarLoader" as JL
participant "ClassLoaderSwapper" as CLS
participant "Plugin Instance" as PI
JC -> LU : loadJobPlugin(READER, "mysqlreader")
activate LU
LU -> LU : 查询 pluginRegisterCenter\n获取插件配置(class, path)
LU -> LU : getJarLoader(READER, "mysqlreader")
alt jarLoaderCenter 未缓存
LU -> JL : new JarLoader(pluginPath)
activate JL
JL -> JL : 递归扫描目录收集 *.jar
JL -> JL : 转为 URL[] 传给 URLClassLoader
JL --> LU : JarLoader 实例
deactivate JL
LU -> LU : 缓存到 jarLoaderCenter
end
LU -> LU : loadPluginClass(READER, name, Job)
note right: 拼接类名: className + "$Job"
LU -> JL : loadClass("...MysqlReader$Job")
JL --> LU : Class<?>
LU -> PI : clazz.newInstance()
LU --> JC : Reader.Job 实例
deactivate LU
JC -> CLS : setCurrentThreadClassLoader(jarLoader)
note right: 保存原始 ClassLoader
JC -> PI : init() / split() / prepare() ...
JC -> CLS : restoreCurrentThreadClassLoader()
note right: 恢复原始 ClassLoader
@endumlLoadUtil (core/.../util/container/LoadUtil.java) 核心逻辑:
bind(Configuration)在启动时将ConfigParser解析好的插件配置注册到pluginRegisterCenter。loadPluginClass通过内部类命名约定(ClassName$Job/ClassName$Task)定位具体实现类。jarLoaderCenter(Map)缓存已创建的 JarLoader,避免重复加载。
JarLoader (core/.../util/container/JarLoader.java) 继承 URLClassLoader,构造时递归扫描指定目录下的所有 *.jar 文件并转为 URL 数组。
ClassLoaderSwapper (core/.../util/container/ClassLoaderSwapper.java) 提供 setCurrentThreadClassLoader / restoreCurrentThreadClassLoader 配对方法,在每次插件调用前后切换线程上下文 ClassLoader,确保插件代码能找到自身依赖的类。
3.4.3 常见Reader/Writer实现分析
StreamReader(最简实现)
StreamReader (streamreader/.../StreamReader.java) 是一个无外部数据源的测试 Reader,结构展示了标准的插件开发模式:
public class StreamReader extends Reader {
public static class Job extends Reader.Job {
@Override
public List<Configuration> split(int adviceNumber) {
// 简单地将配置克隆 adviceNumber 份
List<Configuration> configs = new ArrayList<>();
for (int i = 0; i < adviceNumber; i++) {
configs.add(this.originalConfig.clone());
}
return configs;
}
}
public static class Task extends Reader.Task {
@Override
public void startRead(RecordSender recordSender) {
// 按配置生成指定数量的记录
Record record = recordSender.createRecord();
// 填充 Column(支持常量值和 random 随机值)
recordSender.sendToWriter(record);
}
}
}支持 6 种数据类型(STRING/LONG/BOOL/DOUBLE/DATE/BYTES)和 random 随机生成函数。
MysqlReader(委托模式)
MysqlReader (mysqlreader/.../MysqlReader.java) 是一个薄包装器,核心逻辑全部委托给 CommonRdbmsReader:
public class MysqlReader extends Reader {
public static class Job extends Reader.Job {
private CommonRdbmsReader.Job commonJob;
@Override
public void init() {
// MySQL 特化:强制设置 fetchSize = Integer.MIN_VALUE(流式读取)
this.commonJob = new CommonRdbmsReader.Job(DATABASE_TYPE.MySql);
this.commonJob.init(this.originalConfig);
}
@Override
public List<Configuration> split(int adviceNumber) {
return this.commonJob.split(this.originalConfig, adviceNumber);
}
}
}CommonRdbmsReader.Task.startRead() 执行 SQL 查询,逐行遍历 ResultSet 并通过 transportOneRecord() 将 JDBC 类型映射为 DataX Column 类型(VARCHAR→StringColumn, BIGINT→LongColumn 等),异常记录通过 TaskPluginCollector.collectDirtyRecord 收集。
3.4.4 插件开发模式
标准的 DataX 插件由以下三部分组成:
1. 外层类 + Job/Task 内部类
public class XxxReader extends Reader {
public static class Job extends Reader.Job {
@Override public void init() { /* 校验配置 */ }
@Override public List<Configuration> split(int adviceNumber) { /* 拆分任务 */ }
@Override public void destroy() { /* 释放资源 */ }
}
public static class Task extends Reader.Task {
@Override public void init() { /* 提取 Task 级配置 */ }
@Override public void startRead(RecordSender sender) { /* 读取数据并发送 */ }
@Override public void destroy() { /* 释放连接 */ }
}
}2. plugin.json 描述文件
{
"name": "xxxreader",
"class": "com.xxx.plugin.reader.XxxReader",
"description": "读取 Xxx 数据源",
"developer": "xxx"
}name 与作业 JSON 中 reader.name 对应;class 为外层类全限定名,框架通过 class + "$Job" / class + "$Task" 定位内部类。
3. 生命周期回调
| 回调方法 | Job 级 | Task 级 | 用途 |
|---|---|---|---|
init() | Y | Y | 配置校验、连接测试 |
prepare() | Y | Y | 建表、清理目标数据 |
split() | Y | - | 拆分数据片段 |
startRead/startWrite | - | Y | 数据读写主逻辑 |
post() | Y | Y | 提交事务、重命名文件 |
destroy() | Y | Y | 关闭连接、释放资源 |
3.5 并行化处理与任务拆分
3.5.1 任务拆分算法
任务拆分的完整流程位于 JobContainer.split() (core/.../job/JobContainer.java:386):
@startuml
start
:adjustChannelNumber()\n计算所需 Channel 数;
note right
优先级:byte限速 > record限速 > channel直接指定
取 byteChannel 和 recordChannel 的较小值
end note
if (needChannelNumber <= 0) then (是)
:needChannelNumber = 1;
endif
:doReaderSplit(needChannelNumber)\n调用 Reader.Job.split(adviceNumber);
:taskNumber = readerTaskConfigs.size();
:doWriterSplit(taskNumber)\n调用 Writer.Job.split(mandatoryNumber);
note right: Writer 必须返回与 Reader 等量的 Task
:获取 transformer 配置列表;
:mergeReaderAndWriterTaskConfigs()\n将 Reader/Writer Task 1:1 合并;
note right
每个 content 元素包含:
reader.name + reader.parameter
writer.name + writer.parameter
transformer (可选)
taskId (顺序编号)
end note
:写回 configuration.job.content;
stop
@endumladjustChannelNumber() 的计算逻辑:
- 若配置了
job.setting.speed.byte(全局字节限速),则channelByByte = globalByteSpeed / channelByteSpeed。 - 若配置了
job.setting.speed.record(全局记录限速),则channelByRecord = globalRecordSpeed / channelRecordSpeed。 - 取两者较小值。若两者均未配置,则使用
job.setting.speed.channel直接指定。 - 三者都未配置则抛出异常。
3.5.2 任务调度策略
JobAssignUtil.assignFairly() (core/.../container/util/JobAssignUtil.java) 实现了资源感知的公平分配算法:
- 计算 TaskGroup 数量:
taskGroupNumber = ceil(channelNumber / channelsPerTaskGroup)。 - 提取资源标记:从每个 Task 的 reader/writer 配置中获取
loadBalanceResourceMark(如数据库实例标识),若无则注入随机标记并 shuffle。 - 按资源分组:将 Task 按资源标记归类为
LinkedHashMap<String, List<Integer>>。 - 轮询分配:遍历每个资源组,将其 Task 轮询分配到不同 TaskGroup,确保同一资源的 Task 分散到不同 TaskGroup。
- 调整 Channel 数:为每个 TaskGroup 计算实际 Channel 数(平均分配,余数轮询分到前几个 TaskGroup)。
示例(代码注释中的场景):
数据库A: 表 0,1,2 数据库B: 表 3,4 数据库C: 表 5,6,7
4 个 TaskGroup 分配结果:
TaskGroup-0: [0, 4] // A的表0, B的表4
TaskGroup-1: [3, 6] // B的表3, C的表6
TaskGroup-2: [5, 2] // C的表5, A的表2
TaskGroup-3: [1, 7] // A的表1, C的表7
3.5.3 负载均衡机制
负载均衡基于 loadBalanceResourceMark 资源标识实现。当 Reader 插件在 split() 时为每个 Task 配置设置 loadBalanceResourceMark(通常为数据库连接地址),框架在分配时会将相同资源标记的 Task 分散到不同 TaskGroup。
工作流程:
- Reader 在 split 时设置
configuration.set("loadBalanceResourceMark", jdbcUrl)。 JobAssignUtil解析所有 Task 的资源标记,建立resourceMark → taskIdList的映射。- 轮询分配确保同一数据库的多个表读取不会集中在同一个 TaskGroup,避免单个数据源成为瓶颈。
- 若插件未设置资源标记,框架注入随机标记并 shuffle 任务顺序,退化为均匀随机分配。
3.5.4 并行度控制
DataX 的并行度由两个层级控制:
Job 级别 — channelNumber 计算(JobContainer.adjustChannelNumber()):
| 优先级 | 配置项 | 说明 |
|---|---|---|
| 1 | job.setting.speed.byte | 全局字节限速,channelNumber = globalByteSpeed / channelByteSpeed |
| 2 | job.setting.speed.record | 全局记录限速,channelNumber = globalRecordSpeed / channelRecordSpeed |
| 3 | job.setting.speed.channel | 直接指定 channel 数量 |
若同时配置了 byte 和 record 限速,取计算出的较小值。最终 needChannelNumber = min(计算值, 实际Task数)。
TaskGroup 级别 — channelsPerTaskGroup:
- 配置项
core.container.taskGroup.channel,默认为 5。 - TaskGroup 数量 =
ceil(channelNumber / channelsPerTaskGroup)。 - 每个 TaskGroup 内同时运行的 TaskExecutor 数量不超过分配到的 channel 数。
3.6 容错与监控机制
3.6.1 统计信息收集
DataX 的统计信息以 Communication 对象为核心载体,采用分层收集架构:
- Task 级:
ReaderRunner/WriterRunner在执行过程中通过Channel.statPush()/statPull()更新读写字节数和记录数。 - TaskGroup 级:
TaskGroupContainer定期将所有 Task 的 Communication 聚合后上报。 - Job 级:
AbstractScheduler定期从ContainerCommunicator收集所有 TaskGroup 的聚合状态。
CommunicationTool (core/.../statistics/communication/CommunicationTool.java) 定义了完整的指标体系:
| 指标 | 含义 |
|---|---|
READ_SUCCEED_RECORDS/BYTES | 成功读取的记录数/字节数 |
READ_FAILED_RECORDS/BYTES | 读取失败的记录数/字节数 |
WRITE_RECEIVED_RECORDS/BYTES | Writer 接收到的记录数/字节数 |
WRITE_FAILED_RECORDS/BYTES | 写入失败的记录数/字节数 |
BYTE_SPEED / RECORD_SPEED | 实时字节速率/记录速率 |
WAIT_READER_TIME / WAIT_WRITER_TIME | Reader/Writer 等待 Channel 的时间 |
TRANSFORMER_SUCCEED/FAILED/FILTER_RECORDS | Transformer 处理统计 |
CommunicationTool.getReportCommunication(now, old, totalStage) 通过前后两个 Communication 快照计算增量速率:bytesSpeed = (newBytes - oldBytes) / timeInterval。
3.6.2 Communication通信模型
Communication (core/.../statistics/communication/Communication.java) 是线程安全的统计容器,支持层级聚合:
@startuml
package "Task Level" {
[Task-0 Communication] as T0
[Task-1 Communication] as T1
[Task-2 Communication] as T2
}
package "TaskGroup Level" {
[TaskGroup-0 Communication] as TG0
[TaskGroup-1 Communication] as TG1
}
package "Job Level" {
[Job Communication] as JOB
}
T0 --> TG0 : mergeFrom()
T1 --> TG0 : mergeFrom()
T2 --> TG1 : mergeFrom()
TG0 --> JOB : mergeFrom()
TG1 --> JOB : mergeFrom()
note bottom of JOB
Scheduler 定期 collect() 聚合
并通过 report() 上报
end note
@enduml核心数据结构:
counter(ConcurrentHashMap):存储 Long/Double 类型的指标,mergeFrom时执行累加。state(State 枚举):合并优先级为FAILED/KILLED > RUNNING > SUCCEEDED,一旦设为 FAILED 则非 force 模式无法覆盖。throwable:保留第一个异常。message(ConcurrentHashMap):收集各 Task 的自定义消息。
mergeFrom(Communication) 将源的 counter 累加到目标,state 按优先级合并,throwable 保留先到的异常。
3.6.3 异常处理与重试机制
DataX 的异常处理分为三个层面:
@startuml
start
:Task 执行中产生异常;
if (脏数据异常?) then (是)
:TaskPluginCollector.collectDirtyRecord();
:继续处理下一条记录;
else (否)
:ReaderRunner/WriterRunner.markFail(e);
:Communication.state = FAILED;
endif
:TaskGroupContainer 检测到 FAILED;
if (supportFailOver() && attemptCount < maxRetryTimes?) then (是)
:shutdown TaskExecutor;
:重置 Communication;
:等待 taskRetryIntervalInMsec;
:重新入队等待重试;
else (否)
:TaskGroup 标记失败;
:上报异常到 Scheduler;
endif
:Scheduler 周期性检查;
:ErrorRecordChecker 校验脏数据阈值;
if (errorRecords > recordLimit?) then (是)
:抛出异常终止 Job;
elseif (errorRecords/totalRecords > percentageLimit?) then (是)
:抛出异常终止 Job;
else (否)
:继续运行;
endif
stop
@endumlErrorRecordChecker (core/.../util/ErrorRecordChecker.java):
recordLimit:脏数据条数上限(绝对值),配置项job.setting.errorLimit.record。percentageLimit:脏数据百分比上限 [0.0, 1.0],配置项job.setting.errorLimit.percentage。- 若同时配置了两者,
recordLimit优先级更高(会将percentageLimit置 null)。 - 检查时机:
AbstractScheduler.schedule()的监控循环中,每轮 collect 后执行checkRecordLimit和checkPercentageLimit。
Task 级重试:
- 由
TaskGroupContainer管理,条件为Writer.Task.supportFailOver()返回 true 且attemptCount < taskMaxRetryTimes(默认 1)。 - 重试前等待
taskRetryIntervalInMsec(默认 10 秒),最大等待taskMaxWaitInMsec(默认 60 秒)。
3.6.4 性能监控与报告
定时汇报:AbstractScheduler.schedule() 循环中每隔 jobReportIntervalInMillSec(默认 30 秒)执行一次 containerCommunicator.report(),输出当前作业的实时快照。
CommunicationTool 提供两种汇报格式:
Stringify.getSnapshot():文本格式,输出总记录数 | 速率 MB/s | 错误数 | Transformer 统计 | 进度百分比。Jsonify.getSnapshot():JSON 格式,包含所有指标的完整序列化(用于远程上报)。
最终统计:JobContainer.logStatistics() 在作业完成后输出汇总信息:
任务启动时刻: 2025-01-01 00:00:00
任务结束时刻: 2025-01-01 00:01:30
任务总计耗时: 90s
任务平均流量: 10.5MB/s
记录写入速度: 100000rec/s
读出记录总数: 9000000
读写失败总数: 0
若有 Transformer 处理,还会追加 Transformer 成功/失败/过滤记录数的统计。
3.7 扩展特性分析
3.7.1 Transformer数据转换机制
TransformerRegistry (core/.../transport/transformer/TransformerRegistry.java) 管理所有 Transformer 的注册与查找。
6 个内置 Transformer(静态初始化块中注册,名称均以 dx_ 前缀):
| 名称 | 功能 |
|---|---|
dx_substr | 字符串截取 |
dx_pad | 字符串填充 |
dx_replace | 正则替换 |
dx_filter | 按条件过滤记录 |
dx_groovy | Groovy 脚本执行 |
dx_digest | 哈希/摘要生成 |
自定义 Transformer 加载:扫描 {DATAX_HOME}/local_storage/transformer/ 下的子目录,每个子目录需包含 transformer.json(声明 class 属性)和对应的 jar 包。加载时通过 JarLoader 创建独立 ClassLoader,反射实例化后注册。自定义 Transformer 名称不允许使用 dx_ 前缀。
执行链:BufferedRecordTransformerExchanger.doTransformer(Record) 按配置顺序逐个执行 Transformer,若某个 Transformer 返回 null 则表示该记录被过滤,不会发送到 Channel。执行过程中统计 TRANSFORMER_SUCCEED_RECORDS、TRANSFORMER_FAILED_RECORDS、TRANSFORMER_FILTER_RECORDS 等指标。
3.7.2 脏数据处理
脏数据处理通过 TaskPluginCollector 抽象类及其实现完成:
TaskPluginCollector(common/.../plugin/TaskPluginCollector.java):定义了collectDirtyRecord(Record, Throwable, String)等抽象方法,由框架在创建 Task 时注入实现。StdoutPluginCollector(core/.../statistics/plugin/task/StdoutPluginCollector.java):默认实现,将脏数据以 JSON 格式通过LOG.error输出。内置maxLogNum(默认 128,配置项core.statistics.collector.plugin.maxDirtyNum)限制日志量,超出后只计数不输出。
脏数据的典型收集时机:
BufferedRecordExchanger.sendToWriter()中单条记录超过byteCapacity。CommonRdbmsReader.Task.transportOneRecord()中 ResultSet 类型转换失败。- Writer 写入目标数据源时遇到约束冲突或格式错误。
DirtyRecord 工具类将 Record 转为可序列化的格式(各 Column 调用 asString()),用于 JSON 输出。脏数据的总量统计通过 Communication 的 READ_FAILED_RECORDS / WRITE_FAILED_RECORDS 计数器追踪,最终由 ErrorRecordChecker 校验是否超出阈值。
3.7.3 Hook机制
HookInvoker (core/.../container/util/HookInvoker.java) 通过 Java SPI(ServiceLoader)发现并调用外部 Hook:
工作流程:
- 扫描
{DATAX_HOME}/hook/目录下的直接子目录。 - 对每个子目录创建独立的
JarLoader,设为当前线程的 ClassLoader。 - 使用
ServiceLoader.load(Hook.class)查找实现类(需在META-INF/services/com.alibaba.datax.common.spi.Hook中声明)。 - 调用
hook.invoke(configuration, communication.getCounter()),传入作业配置和最终统计指标。 - 恢复原始 ClassLoader。
Hook 接口 (common/.../spi/Hook.java) 仅有两个方法:
public interface Hook {
String getName();
void invoke(Configuration jobConf, Map<String, Number> msg);
}Hook 调用时机:JobContainer.start() 中 postHandle() 之后、invokeHooks() 执行。若 Hook 目录不存在或无 Hook 实现,仅打印 warning 日志,不影响作业正常完成。单个 Hook 异常会被包装为 DataXException(HOOK_INTERNAL_ERROR) 抛出。
3.7.4 资源管理
ClassLoader 隔离:每个 Reader/Writer 插件拥有独立的 JarLoader(缓存在 LoadUtil.jarLoaderCenter),TaskExecutor 创建线程时通过 thread.setContextClassLoader(jarLoader) 注入。ClassLoaderSwapper 在 JobContainer 调用插件 Job 级方法时负责临时切换和恢复,确保插件代码在正确的 ClassLoader 环境中执行。
线程管理:
- TaskGroup 级:
ProcessInnerScheduler创建固定大小的线程池(Executors.newFixedThreadPool(taskGroupNumber)),每个 TaskGroup 一个线程。 - Task 级:
TaskExecutor为每对 Reader/Writer 创建两个独立线程,线程名格式为reader-{taskGroupId}-{taskId}/writer-{taskGroupId}-{taskId}。 - 清理:
TaskExecutor.shutdown()中断 Reader/Writer 线程;ProcessInnerScheduler.dealFailedStat()调用shutdownNow()强制终止所有 TaskGroup。
OOM 保护:
JobContainer.start()的 catch 块特别处理OutOfMemoryError:先调用destroy()释放插件资源,再调用System.gc()尝试回收。- Channel 层通过
byteCapacity(默认 8MB)限制内存占用,MemoryChannel.doPushAll()在内存超限时阻塞等待。 BufferedRecordExchanger对超过byteCapacity的单条记录直接收集为脏数据,不进入缓冲区。